
Thesis
Voice has been the predominant mode of communication throughout human history, making it the most suitable interface for human-computer interaction. In natural conversation, humans typically respond within 200-300 ms, with expressiveness evoked through tone and voice inflection. Voice AI has not caught up. One January 2026 analysis of more than 4 million production voice agent calls across 10K+ deployed agents found that median end-to-end response latency sits at 1.4 to 1.7 seconds, roughly 5x slower than the 300ms threshold humans expect for natural conversation. The tail is worse: 10% of calls exceed 3-5 seconds, and 1% stretch past 8-15 seconds, breaking the conversation entirely. This gap between marketed sub-300ms latencies and the 1.4 to 1.7-second reality is why deployed agents still "feel slow" to users.
The root cause is architectural. Most production voice stacks chain models built on the transformer, a primitive that scales compute quadratically; when input length doubles, compute requirements quadruple. The largest latency contributor in the stack is LLM inference, accounting for roughly 70% of total response time, with each additional component (speech-to-text, text-to-speech, network, turn detection) compounding the delay. When voice AI stalls in response, even by a quarter of a second, and fails to "demonstrate emotional intelligence," it "breaks the illusion of a natural, human-like exchange." On the quality side, Mean Opinion Scores (the gold standard for TTS naturalness) only reach speech "rivaling human" at 4.3 to 4.5 on a 5-point scale, a bar that most production deployments still don't clear. Because conversational AI requires efficient, real-time processing of large volumes of data, transformer-based stacks are structurally mismatched to the workload.
Of the 80% of businesses using traditional voice AI systems in 2025, only 21% were satisfied with them. However, 67% of organizations in the same year consider “voice AI core to their product and business strategy.” This is because voice agents are significantly less costly than humans in domains like customer support. One report in June 2025 noted that, "while a 15-20 person call center costs upwards of $1 million annually, a voice AI agent costs less than a single full-time hire — and it comes pre-trained, integrated into systems, and immune to burnout (more importantly, turnover)." Further, effective conversational AI increases revenue creation opportunities for businesses, as they can “immediately pick up and answer every call, 24/7 and in any language, ensuring that no opportunity is missed, no customer is left hanging, and every call becomes a touchpoint for conversion or retention."
Cartesia seeks to address the shortcomings of the legacy voice AI stack with a new model architecture, the State Space Model (SSM), that processes data far more efficiently than the transformer. This makes the SSM more useful for delivering voice AI experiences that resemble authentic human speech patterns. The company has productized the SSM by building voice models with extremely low latency and natural expressiveness. It also offers an agent development platform that allows businesses to easily create voice agents with its models and infrastructure.
Founding Story

Source: Cartesia
Cartesia was founded in September 2023 by Karan Goel (CEO), Albert Gu (Chief Scientist), Arjun Desai, Brandon Yang, and Stanford AI Lab research advisor Christopher Ré. Goel, Gu, Desai, and Yang initially crossed paths as PhD students at Stanford, where they were each advised by Ré within the Stanford AI Lab. Under Ré, the team invented State Space Models (SSMs), a new architecture for training large-scale foundation models that is more efficient and cheaper than transformers. Upon their graduation from Stanford in 2023, the team co-founded Cartesia to productize the SSM.
Christopher Ré: Re is a professor of Computer Science at the Stanford AI Lab. He is also part of Stanford’s Center for Research on Foundation Models. While Goel, Desai, Yang, and Gu were enrolled as PhD students at Stanford, Ré advised them throughout the development of the State Space Model. When the team productized the SSM by founding Cartesia, Ré was named a co-founder. Beyond the State Space Model, Ré has served as a founding member of other academic projects that eventually became notable companies, including Together AI and Snorkel AI. His research has also been “used in products from companies like Apple, Google, YouTube, and more.”
Karan Goel: Goel grew up in India, where his family has been operating a lab equipment business since 1897. He lived across the street from his family’s beaker and microscope factory, where he observed his parents and grandparents continue the entrepreneurial endeavor throughout his childhood. He went on to complete his undergraduate degree in Electrical Engineering at the Indian Institute of Technology, Delhi, before moving to the United States to attend Carnegie Mellon, where he graduated in 2018 with a Master’s degree in Machine Learning. He then pursued a PhD at Stanford, where he started working under Ré in the Stanford AI Lab. Clearly, observing his family build and maintain a business for generations may have influenced his eventual path toward co-founding and becoming CEO of his own company.
Albert Gu: While being advised by Ré during his PhD at Stanford, Gu was apprehensive about the scalability of the transformer architecture and wondered how to develop faster, cheaper, and more capable deep learning architectures that deliver low latency for real-time applications. Goel recounted Gu’s intrigue with this domain, in that “the way that these models are scaling, the quadratic scaling on transformers is going to be a huge bottleneck when you start trying to put a lot of information into them.”
Gu, Goel, and Ré together published their first research paper on structured state spaces in October 2021. Contrary to traditional transformer-based architectures, “SSMs enable continuous, real-time processing, allowing models to handle long input sequences while dramatically improving latency, cost, and scalability.”
Gu continued his research in this area, presenting his PhD dissertation on structured state-space sequence models in June 2023. Within it, he referenced Goel as “instrumental in the development of research toward the later part of [his] PhD, including many of the results” in the thesis. Beyond developing the foundational research that led to the SSM and co-founding Cartesia in September 2023, Gu joined the faculty at Carnegie Mellon as an Assistant Professor of Machine Learning in August 2023, where he continues to serve in this role as of March 2026. Gu also mentioned that Desai and Yang were great friends of his within the Stanford AI Lab.
Arjun Desai: Desai’s education and experience span medicine, engineering, and computer science. His time at Stanford from 2019 to 2023 as an electrical engineering PhD student led him to the Stanford AI Lab, where he first met Ré, his faculty advisor. As an undergrad at Duke between 2014 and 2018, he studied Biomedical Engineering and Computer Science. Desai interned at Microsoft in Summer 2016, where he focused on enhancing page loading speeds and cache optimization. Between 2016 and 2018, he worked in a vision and image processing lab at Duke, focusing on high-resolution image processing for ophthalmic care and developing a method for neonatal prematurity classification. He continued his interest in the medical field by interning at Verily Life Sciences, an AI-native precision health platform, in Summer 2019, and doing research at Stanford University School of Medicine. He also worked on the Apple Intelligence machine learning team at Apple in 2022.
Brandon Yang: Yang did his undergrad and PhD in Computer Science at Stanford, where he was also advised by Ré. While doing his PhD, Yang worked on “ML training and evaluation infrastructure” at Snorkel AI. He also did an AI research residency at Google Brain from June 2018 to December 2019. In 2015 and 2016, he did software engineering internships at Facebook and Asana, respectively.
The State Space Model vs. Incumbent Transformers
For every item (word, number, etc.) in an input corpus, transformers compare each item to every other item to understand how they relate in context. This creates quadratic scaling: each time the sequence length doubles, the number of computations quadruples. State Space Models take a more efficient approach. Rather than comparing every item to every other item, Goel noted that SSMs compress the most important information into a compact summary, similar to how a ZIP folder compresses files, and discards the rest. This enables linear scaling: as sequence length doubles, computational requirements only double rather than quadruple, making SSMs "much more efficient in how [they draw] on computing power." This structural difference has direct cost implications.
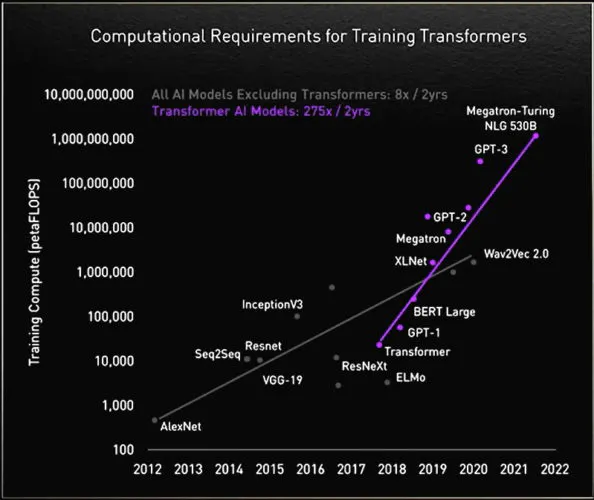
Source: NVIDIA
Transformers' quadratic scaling translates into enormous compute demands. As input lengths grow, memory and computational requirements explode disproportionately, and the numbers bear this out. OpenAI's GPT-3 (2020) had 116x more parameters than GPT-2 (175 billion vs. 1.5 billion) and processed ~50x more tokens (499 billion vs. 10 billion), yet required 1,662x more compute for training. Compute requirements scale far faster than the underlying model size. Tasks like processing entire research papers, writing thousands of lines of code, or analyzing massive datasets become infeasible very quickly. Given Cartesia's objective of building real-time AI systems that continuously stream massive volumes of data from the natural world, the transformer's skyrocketing compute costs render it incompatible with this mission. The SSM's linear scaling, by contrast, is purpose-built for this challenge.
This distinction becomes most consequential when examining how each architecture handles new information over time. Transformers cannot learn continuously as they encounter new data; they are constrained by the limits of their training data, which can quickly become outdated. The State Space Model was built for the opposite: it can natively stream in information from the natural world, compress it into a working memory, and generate outputs based on its continuously updated state. As Goel noted in April 2025: "Like humans have memory, the model has a memory. The model constantly updates itself in response to new information and then uses that information to act. The result is an SSM that serves as an “elegant foundation for training efficient real-time models that can natively stream in information — just like humans."
Applying The State Space Model To Cartesia
One report noted in May 2025 that “voice is how humans naturally communicate. It is how we prefer to share (and overshare). In other words, voice has always been poised to become the dominant way we interact with computers.” Goel also mentioned, “Voice is a really powerful medium of communication for us as humans. It's also one way businesses interact with customers. It’s the way people create content and disseminate it to others. There are a lot of different applications of this in voice.”
In 2023, the team founded Cartesia to productize the State Space Model architecture, starting with voice models using this new primitive. In March 2025, Goel commented on the company’s early ambition: “When we started Cartesia, that was the big goal: we want to build these systems that can plug into the natural world, and take in all of the information very fast, very efficiently just like humans do through the brain.”
Product
Sonic: Text-to-Speech Models
Cartesia's flagship product, Sonic, is a text-to-speech (TTS) model built on its proprietary SSM architecture. Since its launch in May 2024, the model has gone through three generations of rapid improvement.
The original Sonic delivered responses at 135 ms latency and was designed to generate lifelike, ultra-realistic speech. Ten months later, in March 2025, Cartesia launched Sonic 2.0: twice the size of its predecessor yet meaningfully faster, achieving 90 ms latency. Alongside the speed improvement, Sonic 2.0 introduced greater control over complex phrases, including names, emails, phone numbers, and addresses. Cartesia also released Sonic 2.0 Turbo simultaneously, further reducing latency to 40 ms.
Sonic 3.0, released in October 2025, marked a step-change in expressiveness and authenticity. The model captures the full emotional range of human speech, including laughter, tone variation, and subtle emotional shifts, making interactions feel more natural and engaging. It also expanded language support from 15 to 42 languages.
Ink-Whisper: Speech-to-Text Model
Since the release of the first Sonic model in May 2024, Cartesia has focused on the TTS segment of the voice AI infrastructure stack. The Sonic model API had “thousands” of paying customers as of December 2024, which grew to over 10K users by March 2025. However, in June 2025, the company released Ink-Whisper, its first speech-to-text (STT) model. Desai noted that developers’ primary STT model was OpenAI’s whisper-large-v3-turbo. While it was effective at “post-processing long audio files,” it wasn’t designed for real-time voice transcription.
For an STT model to work in enterprise-grade voice AI agents, it would “need to transcribe speech as it happens,” not after the fact. To better meet the needs of modern voice AI agents, Cartesia fine-tuned OpenAI’s Whisper model. As the company describes it, “Whisper was fundamentally made for bulk processing, not live dialogue. So, we rearchitected it into Ink-Whisper, purpose-building it for real-time voice AI.” Its release of Ink-Whisper indicates Cartesia’s desire not only to play in the TTS model segment but also to span the entire voice AI infrastructure stack. The company’s August 2025 release of Line, its voice agent development platform, further points toward this mission.
Line: Agent Development Platform
As of August 2025, “tens of thousands” of developers were using Cartesia’s Ink-Whisper (STT) and Sonic (TTS) models. To make it even simpler for developers to build AI voice agents, the company released Line: a flexible platform for building custom voice agents using Cartesia models, infrastructure, and tooling. The Ink and Sonic voice models underpin every agent built on Line.
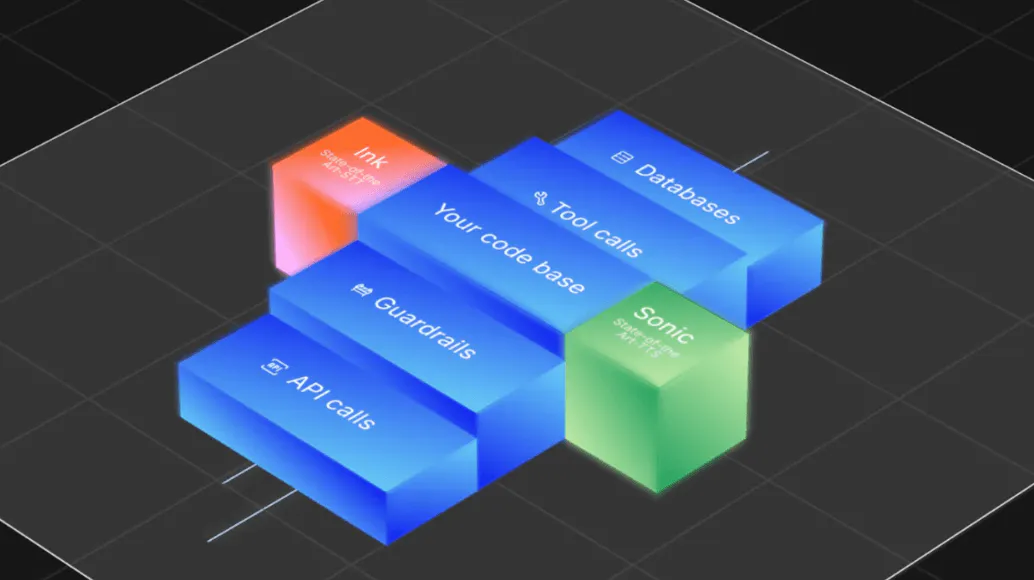
Source: Cartesia
Users have two options for getting started: text prompting and pre-defined templates. Once the user selects a starting point, the platform A/B-tests multiple agent variations in simulated environments to identify the most effective for the use case. This is completed in 5 minutes.
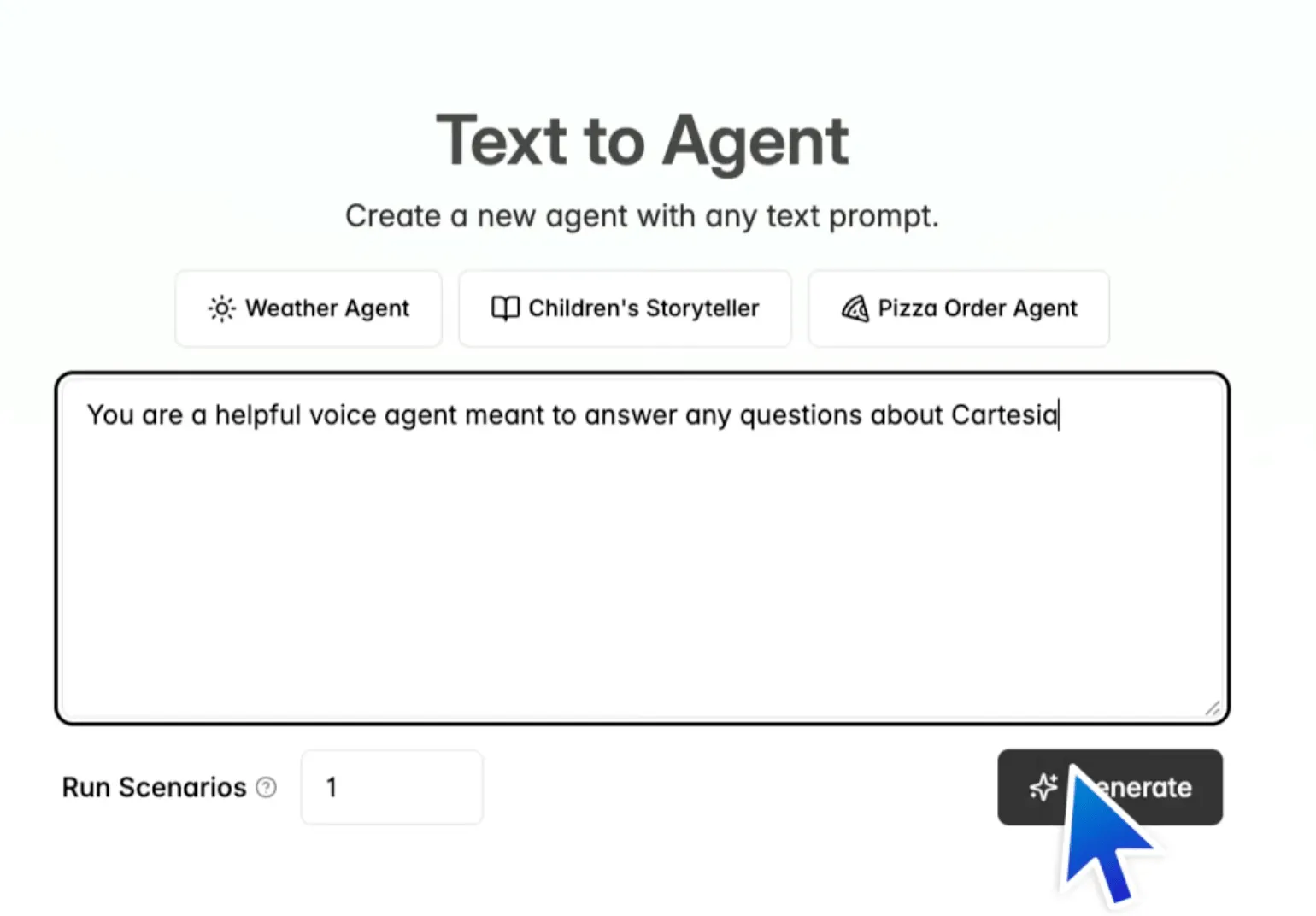
Source: Cartesia
After the simulations are run and the most effective agent is selected for the desired use case, the user chooses a voice they’ve pre-built using the company’s voice models to assign to the agent. Once they are satisfied with it, the developer can download the agent’s code and continue iterating in their integrated development environment (IDE). Cartesia built Line with a code-first approach because of the inflexibility developers often faced with competitors' no-code, drag-and-drop agent builders.
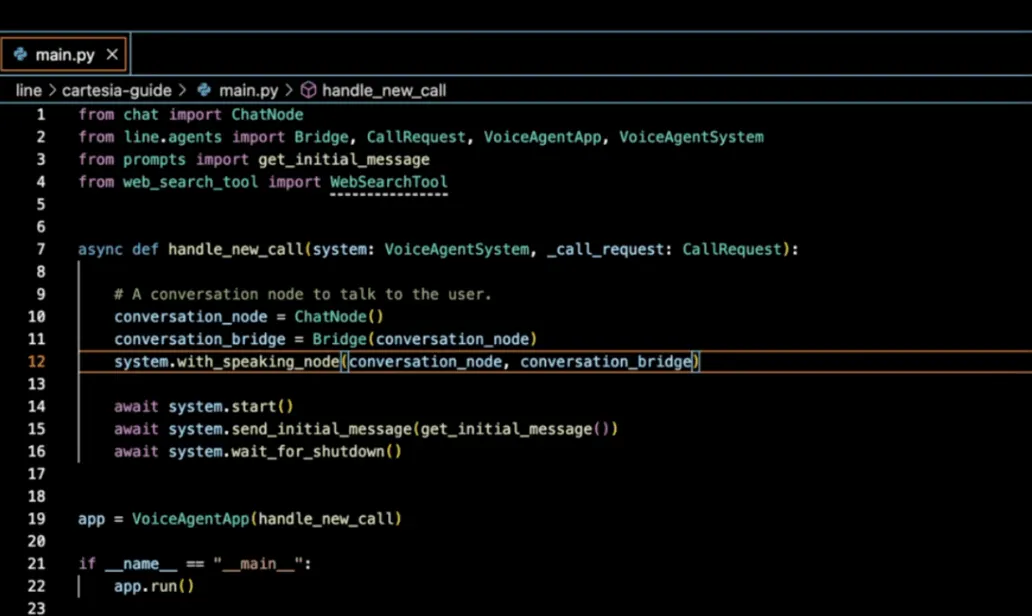
Source: Cartesia
Once users bring their agent’s code into their own development environment, the Line SDK makes it simple for developers to further refine their agent. Users have free reign to add any knowledge or web search integrations they want, with just a few lines of code.
The Line SDK also lets developers easily add background agents that listen to all conversations that the voice agent has with humans, collect data from them in a structured format, and make it easily accessible for later use. Lastly, to help with agent evaluation, Line “records all calls to deployed agents, saves the audio and transcripts, reports system metrics like latency, and provides comprehensive logs for auditing and debugging.”
Market
Customer
As of March 2026, Cartesia serves over 50K companies ranging from startups to global enterprises. The company’s customer base grew quickly, reaching over 10K customers in March 2025. Use cases for the company’s voice models span the application layer, powering voice agents across customer support, sales, recruiting, logistics, marketing, advertising, media, and even gaming.
Customer support appears to be the leading use case as of March 2026, with Cartesia powering voice agents for companies such as Forethought, Decagon, VAPI, Assort Health, MavenAGI, and Regal. Its models are also used by larger enterprise software vendors that are adding voice experiences on top of their core platforms, including ServiceNow. Overall, the broad set of use cases for Cartesia’s voice models has helped the company rapidly scale its customer base.
From an end-user perspective, Cartesia provides models, infrastructure, and tools for developers building real-time voice applications. One 2024 voice AI report commented on the preferences of developers building voice agents:
“Most developers building a voice agent prefer to focus on creating the business logic and customer experience unique to their product rather than managing the infrastructure and models,” which underpin the agent itself.
Cartesia fills this need. In a May 2025 post, Goel noted that “As a model builder focused on voice AI developers, we spend all our time thinking about what developers using Cartesia need from our platform.”
Market Size
The Voice AI infrastructure market was valued at $5.4 billion in 2024 and is projected to reach $133.3 billion by 2034, a 37.8% CAGR. Humans have always been predisposed to communicate with computers through speech. However, until mid-2024, conversational AI stacks relying upon transformer architecture couldn’t deliver fast enough response times, resulting in poor user experiences. Of the 80% of businesses using conversational AI systems in 2025, only 21% were satisfied with them. As new model architectures have widely solved latency and emotional expressiveness issues, “real business usage has exploded… quickly across industries.” Put simply, “voice AI isn’t just an upgrade to software’s UI: it’s transforming how businesses and customers connect.”
The reason 67% of organizations in 2025 consider “voice AI core to their product and business strategy” is that the technology drastically reduces labor overhead and can significantly scale revenue. As noted in June 2025, "While a 15-20 person call center costs upwards of $1 million annually, a voice agent costs less than a single full-time hire — and it comes pre-trained, integrated into systems, and immune to burnout (more importantly, turnover)." Beyond cost reduction, voice agents equip businesses with tooling needed to provide value for users, in scenarios when they previously could not. By deploying voice AI, businesses can “immediately pick up and answer every call, 24/7 and in any language, ensuring that no opportunity is missed, no customer is left hanging, and every call becomes a touchpoint for conversion or retention."
Overall, the shared dissatisfaction of businesses and users with legacy conversational AI solutions, the clear business value of the technology in reducing costs and generating net new revenue, and the readiness of the underlying infrastructure stack are converging. These factors are driving voice AI to become the primary modality for human-to-computer and business-to-audience communication at scale. As Tom Hulme puts it, “After decades of adapting ourselves to technology, ‘technology is finally adapting to us.’”
Competition
OpenAI
OpenAI was founded in 2015. The company has "clearly positioned itself as the defining company of the generative AI era." The launch of ChatGPT in November 2022 drastically expanded access to prompt-based interaction with LLMs to the general public. Within 5 days of launch, the platform gained 1 million users.
The user base hasn't slowed in growth. As of September 2025, ChatGPT has garnered almost 800 million weekly active users. As of June 2025, OpenAI surpassed 3 million business customers. Although this user base predominantly uses ChatGPT and OpenAI's LLMs, OpenAI also provides models spanning other modalities, including audio.
OpenAI's existing customer relationships create a significant distribution advantage for its voice AI products. The company already serves millions of businesses integrating OpenAI's LLMs into their products. The appeal of a one-stop shop for models spanning all modalities may outweigh the benefits of working with a specialized single-modality provider like Cartesia.
OpenAI entered real-time voice AI with gpt-realtime in August 2025, a speech-to-speech model for customer support applications. Early adopters include T-Mobile, Zillow, and StubHub. However, the model offers limited voice customization, with only 10 pre-defined, compared to Cartesia's 500+ voices and voice-cloning functionality.
Cartesia's chained architecture (Ink STT → LLM → Sonic TTS) typically introduces latency, but its SSM implementation achieves ultra-low latency despite this approach. OpenAI also offers standalone STT and TTS models that can be chained for real-time applications, though this approach has higher latency than gpt-realtime and is primarily intended for users appending voice capabilities to existing text-based agents.
The key question is whether Cartesia's performance advantage and developer focus can offset OpenAI's distribution and integration advantages. Cartesia must excel in areas where milliseconds matter (real-time conversation and on-device processing) to defend against OpenAI's bundled offering.
ElevenLabs
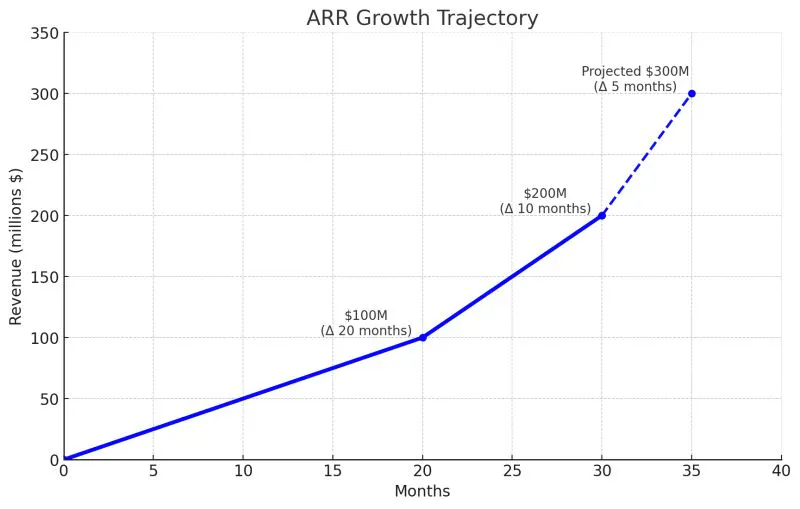
ElevenLabs, founded in 2022, provides an end-to-end AI voice generation platform. This includes TTS and STT models, an agent orchestration platform released in November 2024, and a content editing platform designed for creative use cases. In November 2025, the company announced an employee tender at a $6.6 billion valuation, enabling employees to sell up to $100 million in stock to existing investors, including Sequoia Capital, Andreessen Horowitz, and ICONIQ. This transaction doubled the company’s $3.3 billion valuation from its Series C, raised in January 2025. ElevenLabs has achieved significant revenue growth, surpassing $200 million in ARR in August 2025 and $330 million in ARR as of January 2026. By May 2026, ElevenLabs had announced it had reached $500 million ARR.
Source: Mati Staniszewski
Both ElevenLabs and Cartesia offer TTS and STT models, but Cartesia achieves lower latency across both. On the TTS side, Sonic 2.0 Turbo delivers 40ms latency, compared to 75ms for Eleven Flash v2.5, the fastest TTS model from ElevenLabs. On the STT side, Cartesia's Ink model achieves a 66ms time-to-complete transcript, while ElevenLabs' fastest real-time STT model, Scribe v2 Realtime, delivers partial transcriptions in 150ms.
The two companies diverge more meaningfully at the platform layer. ElevenLabs launched its agent orchestration platform in November 2024, roughly nine months before Cartesia released its own agent platform, Line, in August 2025. By September 2025, over 2 million AI voice agents had been built on ElevenLabs' platform, and CEO Mati Staniszewski has noted that the company's momentum is heavily driven by continued investment in expanding it.
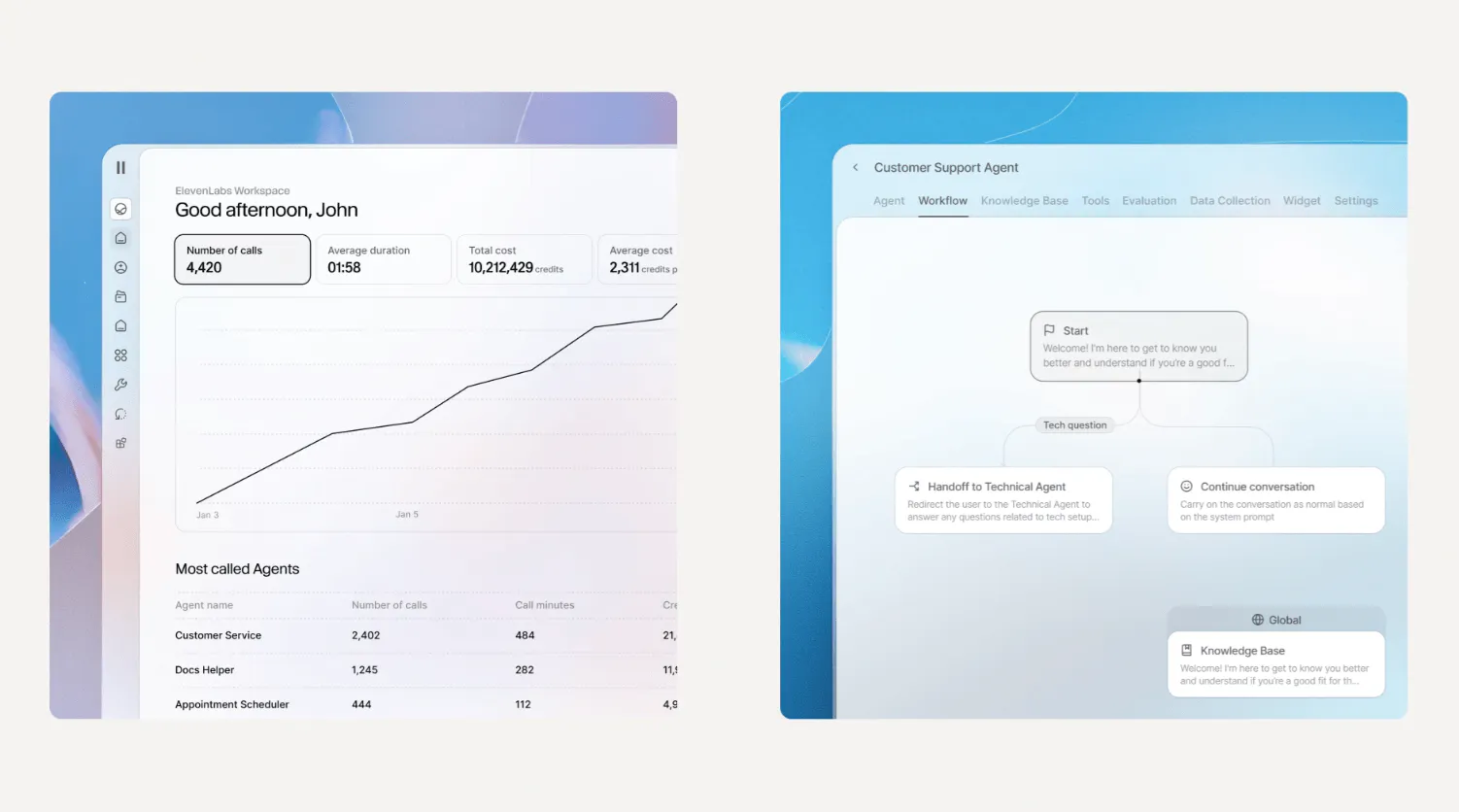
Source: ElevenLabs
That head start is also reflected in the depth of ElevenLabs' tooling. As of March 2026, Cartesia's APIs are explicitly described as "purpose-built for developers." Line offers some no-code entry points, such as a text prompt and pre-built templates, to get to a first draft quickly, but the remainder of the agent development experience is code-first: integrating knowledge sources and background agents is done in a developer's IDE, supported by Cartesia's SDKs and APIs, with no drag-and-drop interface. ElevenLabs, by contrast, supports both technical and non-technical users. Developers can work directly with its suite of SDKs and APIs, while non-developers can build agents end-to-end using a no-code interface.
ElevenLabs has also expanded well beyond agent development into creative and consumer use cases that Cartesia has not pursued. Studio 3.0, released in October 2025, gives video creators, podcasters, and audiobook authors access to every ElevenLabs model in a single editor, with a timeline interface similar to Adobe Premiere for adding voiceovers, background music, and sound effects. Its Reader mobile app, launched in August 2024, lets users upload any text-based file and listen to it in any voice or language.
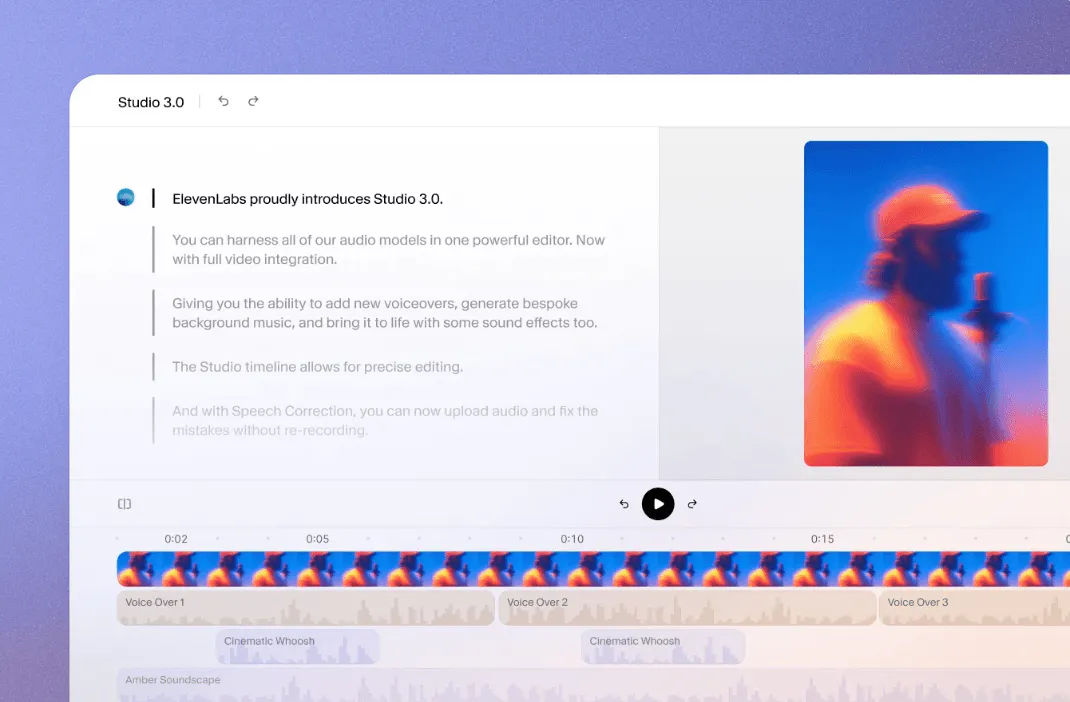
Source: ElevenLabs
Taken together, Cartesia is squarely focused on developers and commercial applications, prioritizing the lowest-latency voice models on the market, in line with its vision to support applications that require real-time intelligence and processing. ElevenLabs has built a broader platform, and while its models and voice customization are comparable to Cartesia's, its no-code tooling, creative suite, and consumer app have allowed it to reach non-technical users and expand its total addressable market considerably.
Deepgram
Founded in August 2015, Deepgram provides foundation model APIs for voice AI applications. The company raised a $72 million Series B in March 2024, and as of April 2025, serves over 200K developers and 400+ enterprise customers, including OpenPhone, Five9, Jack in the Box, and NASA, with 3.3x annual usage growth over the prior four years.
Deepgram competes directly with Cartesia in the developer-focused voice AI infrastructure market, and the two companies share a similar starting point: both offer STT and TTS model APIs aimed at developers building voice applications. Where they diverge is in how far each has moved beyond pure model provision. Deepgram has remained focused on infrastructure, offering its models as individual APIs and through a unified Voice Agent API that consolidates STT, TTS, and LLM orchestration into a single endpoint. This simplifies integration for developers building their own agent frameworks without coordinating multiple services. Cartesia, by contrast, has expanded beyond model APIs into agent development tooling with its Line platform, which includes templates for rapid prototyping, an SDK for IDE-based customization, and built-in tooling for testing and deployment.
The two also differ on latency. Deepgram's Nova-3 and Flux STT models deliver around 300ms latency, and its Aura-2 TTS model achieves sub-200ms latency. Cartesia achieves significantly lower latency with Ink STT at 66ms and Sonic Turbo TTS at 40ms, positioning it for use cases where real-time responsiveness is critical.
For teams that want high-quality voice infrastructure with straightforward integration and the flexibility to build their own agent logic on top, Deepgram is a strong fit. Cartesia appeals to teams seeking both best-in-class latency and an end-to-end platform for agent development in a single solution.
Hume
Founded in 2021, Hume builds voice AI models “powered by emotional intelligence.” Hume trains its models on emotion tokens alongside text and speech, enabling them to identify the emotions associated with words in context and deliver speech with an emotionally accurate tone and prosody.
Octave is the company’s TTS model, a voice-based LLM that is trained on speech and emotion, alongside text. This helps it understand “what words mean in context, so it can predict emotions, cadence, and more.” It can be used for non-interactive use cases (audiobooks, podcasts, or voiceovers) and interactive applications like phone calls.
Empathic Voice Interface (EVI) is Hume’s speech-to-speech model family designed for real-time conversational applications. Using a streaming architecture, EVI handles transcription, language generation, and speech synthesis in a unified model. It's primarily used for real-time, interactive applications like phone calls, customer service, and voice assistants.
Like ElevenLabs, Hume offers a content-editing platform for creating audio content using its TTS models. However, Hume focuses primarily on providing model APIs rather than a complete agent development platform. Hume offers its Octave and EVI models through APIs and provides SDKs for integration, but developers must build their own agent infrastructure, testing tools, and deployment systems. In contrast, Cartesia's Line platform includes the full stack needed to build and deploy voice agents: models, infrastructure, development tools, phone number management, performance analytics, and pre-built integrations for adding capabilities like knowledge bases.
Business Model
Cartesia offers five plans, from free to enterprise, each providing access to Sonic & Ink voice models and the Line platform. The plans are predominantly subscription-based, but some items, like Line voice agent call duration, are usage-based. Customers can elect monthly billing or annual billing to get a 20% discount.
There are two primary differences between the plans. First, the number of model usage credits for Sonic TTS and Ink STT models. Second, the number of concurrent API requests that can be processed at a given time by Cartesia’s servers for Sonic, Ink, and Line, respectively.
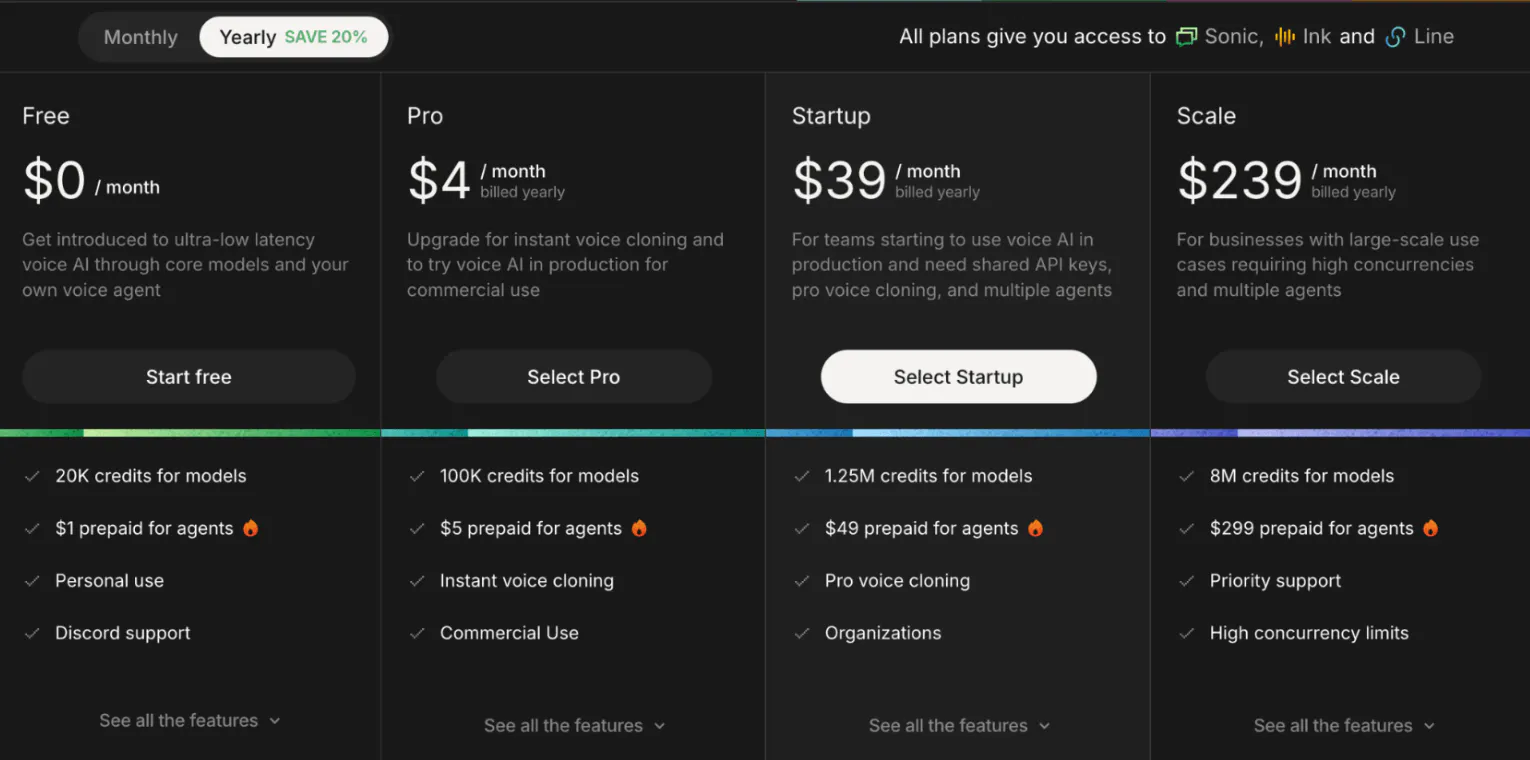
Source: Cartesia
Model Usage Credits
Credits are shared across the Sonic TTS and Ink STT APIs, with Sonic consuming 1 credit per character of text converted to speech and Ink consuming 1 credit per second of audio transcribed. Beyond basic TTS generation, Sonic supports additional features that incur higher-cost credits. Voice changing costs 15 credits per second of audio produced, and localizing a voice into another language costs a one-time fee of 225-credit per voice. Voice cloning is tiered by plan: instant cloning, available from Pro and above, has no upfront cost and charges 1 credit per transcribed character, while pro voice cloning, available from Startup and above, costs 1 million credits to train and 1.5 credits per character of generated speech.
Concurrent API Request Limits
Next, the number of concurrent API calls to the Sonic, Ink, and Line voice agent APIs increases across plans. Concurrent request limits determine how many simultaneous API calls can be made to Sonic, Ink, or Line at any given time, directly constraining the number of parallel voice interactions, such as customer support calls or voice agent conversations, a business can handle at a given time.
For example, the Pro plan provides 3 concurrent TTS API requests, 12 concurrent STT requests, and 12 concurrent calls that Line voice agents can make. The Scale plan provides 15 concurrent TTS API requests, 60 concurrent STT requests, and 60 concurrent calls for Line voice agents.
Line Platform Usage-Based Pricing
For the Line platform, the number of separate voice agents that can be built on the platform scales across the plans, from one on the free plan to ten on the scale plan. On top of the subscription-based model for model credits and concurrent model API calls, Cartesia charges a usage-based rate for phone calls made by Line voice agents, at $0.06 per minute of call duration, and an extra $0.014 per minute to cover the cost of agents using the phone line infrastructure to make calls.
Traction
As of March 2026, revenue growth and product usage metrics are not publicly available. However, Cartesia has scaled its customer base from “thousands” in December 2024 to over 10K customers in March 2025, and to over 50K as of March 2026. This reflects a roughly 5x growth in the customer base in a single year. While the Sonic TTS model API was the company’s “primary line of revenue” as of December 2024, the launch of Ink in June 2025 and Line in August 2025 may have helped further accelerate Cartesia’s customer base expansion and revenue growth.
In November 2025, Cartesia announced a strategic partnership with Tencent Cloud to “advance voice AI for developers.” This indicates further expansion into Asia-Pacific distribution amidst broader global expansion.
Valuation
As of May 2026, no valuation has been publicly disclosed. Between December 2024 to October 2025, Cartesia has raised $191 million from investors and strategic angels, across its seed, Series A, and Series B rounds.
The company's funding journey began with a $27 million seed round in December 2024, led by Index Ventures. Just three months later, in March 2025, Kleiner Perkins led Cartesia's $64 million Series A. In October 2025, Kleiner Perkins followed on by leading Cartesia's $100 million Series B round, joined again by Index Ventures and Lightspeed. NVIDIA also joined as a new strategic investor. Other investors include Lightspeed, A*, Factory, Dell Technologies Capital, Samsung Ventures, and Greycroft.
VC investment in voice AI startups grew from $264 million in 2023 to $2.1 billion in 2024, and $497 million in Q1 2025 alone. This enthusiasm stems from voice being "the most frequent and information-dense form of human communication, and for the first time, AI is making it programmable, unlocking a powerful new interface layer across industries."
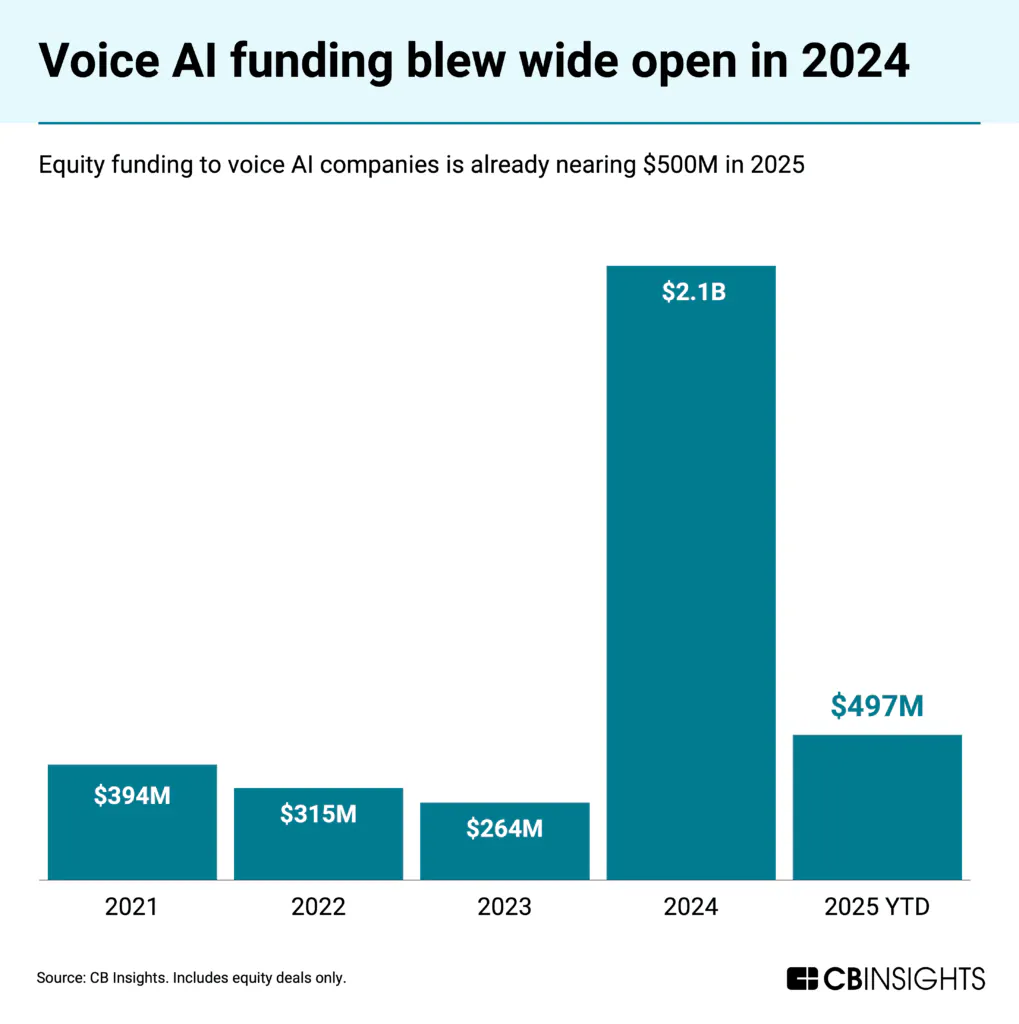
Source: CB Insights
The contrast with just a few years ago is notable. "Voice technology investments were viewed skeptically because of high costs, medium quality, and low customer satisfaction. Today, those barriers are disappearing.” What changed? The convergence of four forces outlined previously: clear business value of AI voice agents, the collapse in voice processing costs that expanded the range of applicable use cases, dissatisfaction with legacy voice AI solutions, and technological breakthroughs that finally delivered the low latency and natural expressiveness that mimic authentic human speech.
Recent M&A activity by large tech companies has further validated the strategic importance of the voice AI market, likely accelerating VC investment in the space. In July 2025, Meta acquired PlayAI, a company comparable to Cartesia that offers an end-to-end platform for building ultra-realistic voice agents. An internal Meta memo noted that "PlayAI's work in creating natural voices, along with a platform for easy voice creation, is a great match for [its] work and roadmap, across AI Characters, Meta AI, Wearables, and audio content creation." This acquisition signals that the largest tech players may view voice AI capabilities as essential infrastructure for their product ecosystems.
Key Opportunities
Vertical AI Voice Agent
Vertical-specific voice agent platforms have emerged across numerous sectors, trained on deep domain data to deliver tailored responses in real time. For example, HappyRobot has emerged as a voice platform for logistics. Its voice agents respond to 100% of all calls, and customers of the platform have achieved a 10x reduction in cost overhead.
EliseAI provides voice and chat-based agents for the real estate industry. Its customers have achieved up to 70% faster approval-to-lease cycles and significant reductions in staffing costs. Toma provides voice agents for automotive dealerships. One customer has attributed $3 million in revenue to using the platform, along with 56 hours of time saved for their team weekly.
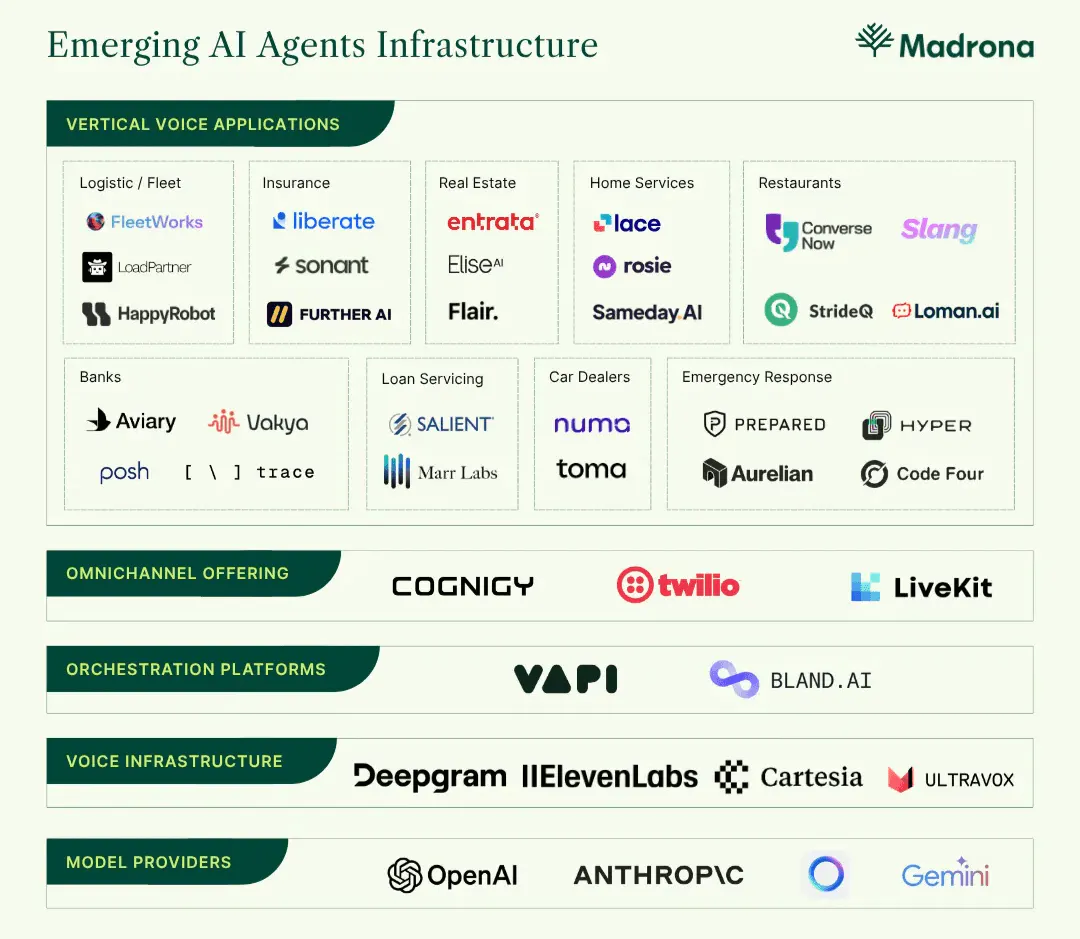
Source: Madrona Ventures
Even the most historically conservative industries, where the implications of an AI mistake are high, have been among the first to adopt the technology: “We are seeing hospitals adopting ‘ambient’ voice agents to automate clinical documentation and relieve burnt-out staff, automating up to 30% of nurses’ documentation and saving hospitals $12 billion annually.”
Because Cartesia’s models have already been adopted by numerous vertical AI voice startups like 11x and Assort Health, the increase in the number of companies building voice AI applications is an opportunity for Cartesia to further scale its customer base.
On-Device AI & New Model Modalities
Since Cartesia’s founding, its mission has been to “build real-time intelligence for every device.” On-device AI was less feasible before the SSM because the transformer couldn’t efficiently process the massive amounts of data constantly streamed from physical environments. However, Cartesia built the SSM to address this constraint, enabling businesses to run AI models directly on-device. The global on-device (or edge) AI market was valued at $25.7 billion in 2025 and is projected to reach over $143 billion by 2034, reflecting a 21% CAGR over the period.
This growth is driven by the far lower latency and enhanced data privacy that edge AI provides. Because information is processed locally rather than in the cloud, latency drops, and there is less surface area for data to be compromised by hackers. On-device AI can also eliminate the need for an internet connection, enabling businesses and consumers in areas with poor connectivity to utilize AI at full capacity. These advantages enable AI use across high-value domains such as robotics, autonomous vehicles, and smart cities.

Source: Figure AI
However, these applications require image and video models, not just voice and language models. In modern robotics, Figure AI’s humanoid robots are trained on vision-language models that unify visual perception and language understanding to complete everyday tasks.
Autonomous vehicles are similar. Waymo’s on-board computer ingests visual “information provided by dozens of sensors on the car, identifies the different objects (like other cars and pedestrians), and plans a safe route towards your destination — all in real time.” Across robotics, autonomous vehicles, and other domains that rely on on-device intelligence, image- and video-based models seem critical.
Cartesia's SSM architecture has only been productized for audio models as of May 2026, but the technology has been applied more recreationally to modalities such as images and video. As Goel stated in May 2024, "audio is just the beginning—we want our models to instantly understand and generate any modality.” If Cartesia can architect new, ultra-efficient image and video models that pair with its existing voice models, the company could become a leading multimodal model provider powering a wide range of real-time, on-device AI applications.
Key Risks
Security Concerns of Voice AI
The rise of voice AI has created an entirely new attack surface for fraud. The line between human and machine has effectively blurred, as those in a November 2025 study failed to identify AI voice deepfakes over 80% of the time. This detection failure is driven by technological advancements that have reduced latency and enhanced emotive expressiveness in voice synthesis, combined with open-source accessibility that has dramatically lowered barriers for fraudsters. As of December 2025, Hugging Face hosts over 3.7K TTS models, up from over 2.4K in 2024, giving fraudsters increasingly broad access to tools for generating hyperrealistic voices.
The result has been a dramatic surge in synthetic voice fraud. Deepfake attacks increased 1,300% between 2023 and 2024, targeting both employees and customers across organizations. In October 2024, Wiz co-founder and CEO Assaf Rappaport noted that an unknown fraudster had sent deepfake voice messages mimicking his voice to request employee credentials. Customer-facing operations have been equally impacted, with contact center voice fraud increasing 26% year-over-year between 2023 and 2024, and 100% since 2021.
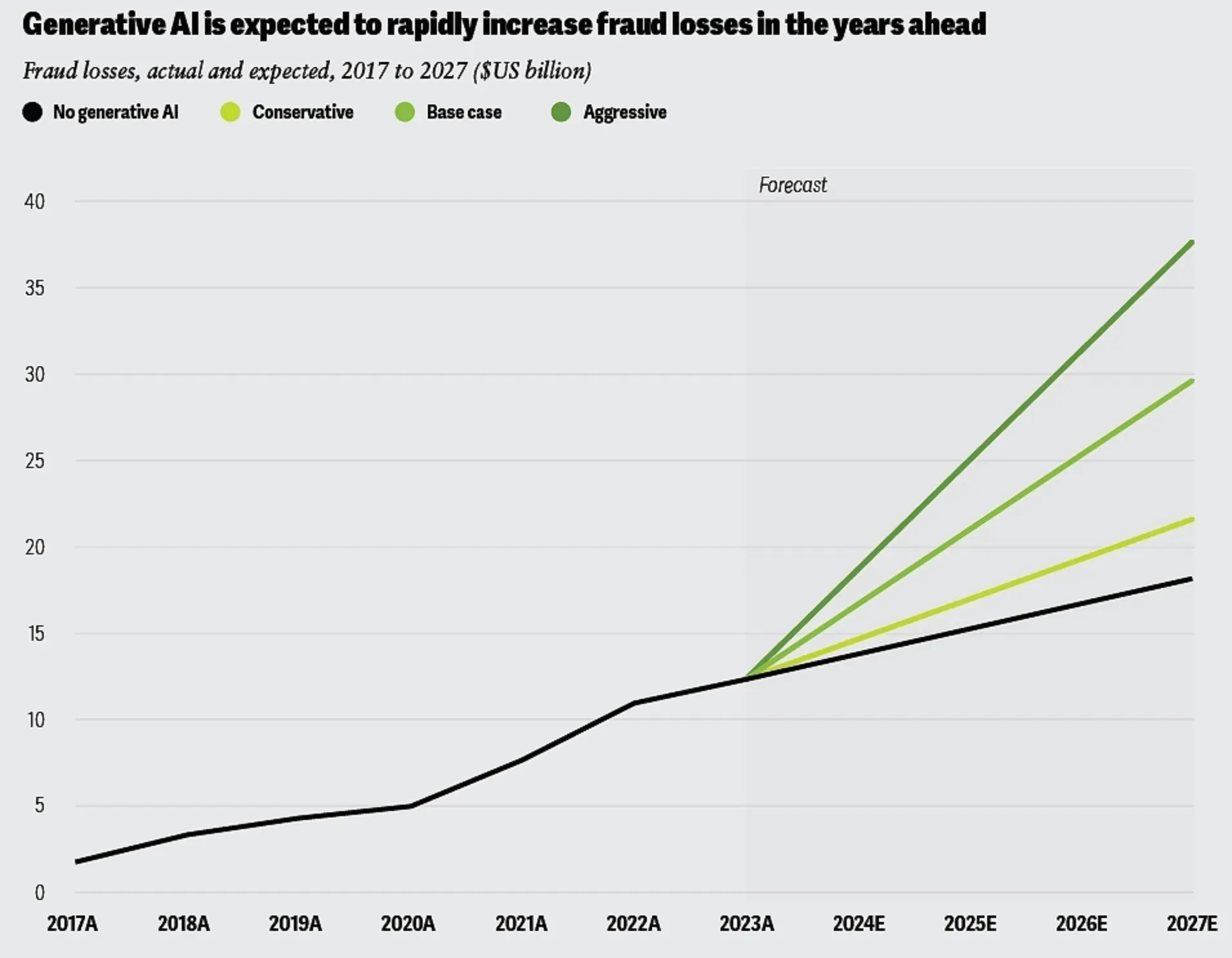
Source: Deloitte
The financial impact of this threat is severe and growing. One 2024 study projected that AI-enabled fraud losses in the United States could reach $40 billion by 2027, up from $12.3 billion in 2023. At the incident level, organizations face average costs of $450K per deepfake attack, with financial services firms incurring over $600K per incident when accounting for both direct costs, such as financial theft, and indirect costs, such as long-term reputational damage.
This deepfake crisis creates a significant adoption barrier for Cartesia. Potential customers may delay adoption due to concerns about enabling fraud vectors, regulatory exposure, or reputational damage from association with voice AI during high-profile incidents. The core challenge is that the same technological capabilities that make Cartesia's product valuable also make it potentially exploitable, creating market headwinds that could slow enterprise adoption. While this is the case, Cartesia announced in September 2025 that its TTS platform achieved GDPR compliance. This builds upon the company’s existing security certifications, including SOC 2 and HIPAA.
Limited Non-Technical Customer Base
As of May 2026, Cartesia has built its product portfolio exclusively for developers. Its model APIs were built to “enable developers to build real-time, multimodal AI experiences.” While competitors’ agent development platforms opted for no-code, drag-and-drop interfaces, Cartesia’s Line platform is code-first, giving developers the highest degree of flexibility to build AI voice agents.
For example, ElevenLabs’s agent orchestration platform offers a no-code, drag-and-drop interface that enables non-technical users to build voice agents, while still providing APIs and SDKs for developers. The company has also expanded into creative and consumer markets. Studio 3.0, released in October 2025, provides video creators, podcasters, and audiobook authors with an integrated editor featuring timeline controls similar to Adobe Premiere. The Reader mobile app, released in August 2024, lets consumers convert any text into speech. Cartesia's exclusive focus on building for technical users may limit its ability to reach non-technical audiences, potentially inhibiting expansion of its total addressable market.
Summary
In 2025, 80% of businesses used incumbent conversational AI systems, but only 21% were satisfied with them. As of mid-2024, models using the transformer architecture in voice AI tech stacks were not efficient enough to deliver fast response times or natural expressiveness that users expect in standard conversation. Cartesia’s thesis is that voice models can deliver faster response times by leveraging the state space model architecture, a more efficient alternative to the transformer.
As of May 2026, Cartesia serves over 50K companies ranging from startups to global enterprises. Use cases for the company’s voice models span the application layer, powering voice agents across customer support, sales, recruiting, logistics, marketing, advertising, media, and even gaming. The broader voice AI infrastructure market is expected to grow from $5.4 billion in 2024 to $133.3 billion in 2034, driven by advances in model architecture and the well-defined ability of effective voice AI agents to reduce labor overhead while enabling revenue growth for businesses across numerous industries and use cases. The key question is whether Cartesia can sustain its growth by deepening adoption among voice AI application providers and enterprise software platforms. Equally opportunistic is its ability to expand into edge computing domains like robotics, smart cities, and autonomous vehicles, where on-device, real-time AI is essential.


